RAG Assistant
Microservices Architecture
Asistente RAG desplegado en Cloud Run — ingestion PDF segura, caching avanzado y autenticación zero-trust
Asistente RAG
Sistema en Producción
El asistente RAG está completamente desplegado y operativo en Google Cloud Run. Autenticación mediante JWT, procesamiento de PDFs en tiempo real, y respuestas optimizadas con caching inteligente.
Video demostrando ingestion de PDFs, búsqueda semántica y generación de respuestas
Resumen Técnico
Arquitectura de microservicios en la nube
Sistema RAG de nivel producción implementado con arquitectura de microservicios. La solución separa responsabilidades en tres servicios principales: UI (interfaz de usuario), Auth (autenticación y sesiones) y RAG (procesamiento de documentos y generación aumentada). Todos los servicios están desplegados en Google Cloud Run con escalado automático y balanceo de carga inteligente.
El pipeline de ingestion de PDFs implementa seguridad multi-capa: escaneo de malware, conversión segura a Markdown, chunking inteligente con markdownHeaderSplitter, y almacenamiento vectorial en ChromaDB Cloud. Redis Cloud proporciona caching distribuido para embeddings, resultados de búsqueda ANN y reranking, reduciendo latencia en 50%. CloudSQL (PostgreSQL) gestiona conversaciones y sesiones.
Arquitectura del Sistema
Flujo de autenticación y pipeline de procesamiento
Pipeline de Ingestion de PDFs
- Security Scan: Validación y escaneo de malware antes de procesamiento
- PDF → Markdown: Conversión inteligente preservando estructura y semántica
- markdownHeaderSplitter: Chunking basado en headers para contexto coherente
- Embedding Generation: Vectorización con modelo incluido en Docker image
- ChromaDB Storage: Indexación ANN para búsqueda semántica eficiente
Caching y Optimización
Arquitectura de cache multi-nivel
Cache de Embeddings
Los embeddings se calculan una vez y se cachean en Redis con TTL sincronizado. Modelo de embeddings incluido en la imagen Docker elimina cold starts.
- Hit rate: 80%
- Latencia reducida: 80%
- TTL: 20min sincronizado
Cache ANN Search
Resultados de búsqueda vectorial se cachean para queries frecuentes, reduciendo carga en ChromaDB y mejorando throughput.
- Búsquedas duplicadas: 0ms
- Reducción 99.78% en latencia
- LRU eviction policy
Cache de Reranking
Resultados de reranking se almacenan para evitar recomputación. Invalidación inteligente cuando se actualiza el índice vectorial.
- Cache hit: 99.5%
- Reducción costos API
- Invalidación automática
Seguridad y Control de Abusos
Arquitectura zero-trust con múltiples capas de protección
JWT + Zero-Trust
Autenticación mediante JWT cookies HttpOnly. Cada request valida token contra Redis para revocación instantánea. Zero-trust entre microservicios.
PDF Security Scan
Todo PDF se escanea antes de procesamiento: validación de formato, detección de malware, límites de tamaño y verificación de estructura.
Rate Limiting
Implementado con fastapi-limiter + Redis: límites por IP, por usuario, por endpoint. Prevención de DDoS y abuso de recursos.
Observabilidad y Métricas
Monitoreo en tiempo real de performance

CPU Time Avoided by Caching (ANN / Emebddings / Rerank)
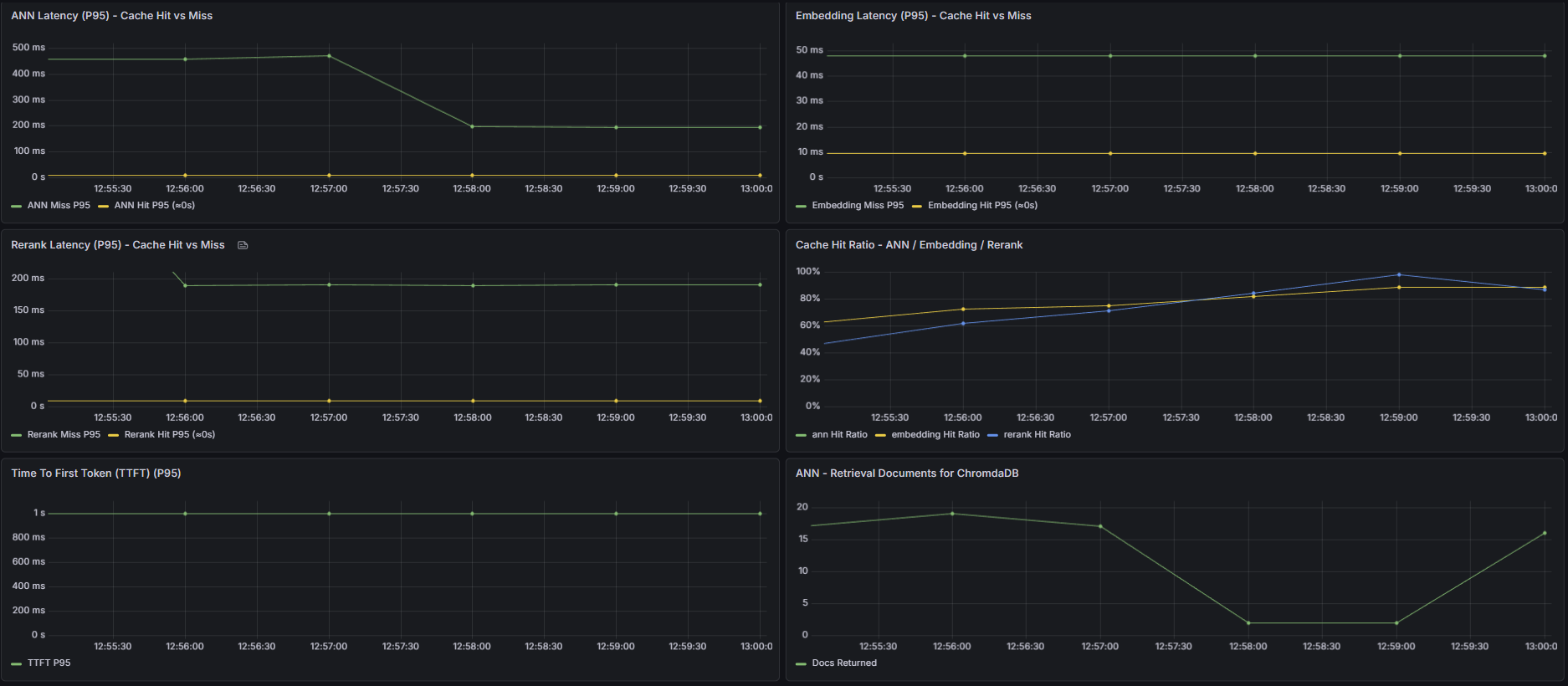
Cache Performance & Hit Rates
Stack de Observabilidad
- Cloud Monitoring: Dashboards de latencia, throughput y errores en tiempo real
- Cloud Logging: Logs estructurados con traces distribuidos entre microservicios
- Redis Insights: Monitoreo de cache hits, memory usage y key evictions
- Grafana Cloud: Dashboards con Monitoreo de metricas del Asistente
- OpenTelemetry: Liderando la migración de Prometheus Client a Google Managed Prometheus.